May 3
(Darker is better in this case)
Four years ago researchers from the Event Horizon Telescope (EHT) project presented the first ever photo of a black hole. The image culminated years of work and gave the world a peek at the enormous spatial object sitting 55-million light years away in the Messier 87 (M87) galaxy. Seeing a black hole in space, an object that’s not only very far away and very massive but also by its very nature doesn’t want to be seen, is not only a physical challenge but requires a lot of technology and work with data.
All images and models of black holes before had been estimations/simulations and the EHT achievement opened up a new era of visualization capabilities. A few years later building on the methodology the EHT team produced an image of the black hole in our own Milky Way galaxy known as Sagittarius A* (Sgr A*). Beyond these two milestones some of the team members at the Institute for Advanced Study in Princeton, N.J. began wondering if advancements in data processing technologies and artificial intelligence could be used to produce a better image from the data. Those researchers have now revealed a clearer, improved version of the original M87 photo made using machine learning techniques.
Big Telescopes and Big Data
How much data must you amass and compute to get an image of an object so far away, so many more times massive than our own Sun, from a network of telescopes that make a dish the size of Earth?

The Possibility For More Data
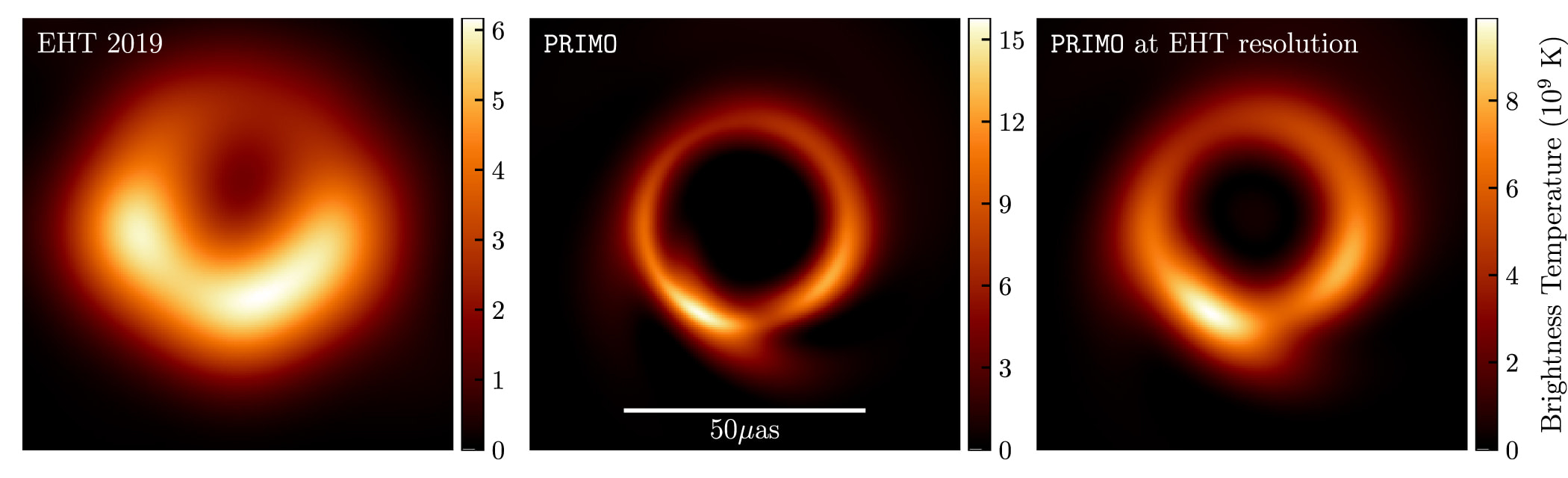
Researchers wondered if the correlation process would produce better results if there was even more data from another source: images generated using machine learning. Creating the final image of the black hole requires combing through collected data and removing noise caused by atmosphere and instruments. At the same time there are spots where data is missing and so smoothing and algorithmic assumptions must be made (contributing to some of the blurriness of the final image). But what if models could be used to generate simulated image data of black holes at a large scale and then applied to “fill in the gaps”? This new approach involved generating a large library of over 30,000 high-fidelity, high-resolution images. Then a process known as principal component analysis (PCA) was applied. Coined PRIMO (principal-component interferometric modeling), it was effectively using PCA to train the models used by machine-learning processes to generate the final images. The simulated data when combined with the EHT observations produced a reconstructed image with improved resolution and accuracy.
Final Image and Implications
What was already a feat of science, technology and data now includes machine-learning in its sphere of influence. The final image rendered from petabytes of data to a few megabytes-sized image has revealing results. A thinner “donut” shape with a darker center making it even more “black hole-like” than the original. The implications to continuing research of black holes and other celestial objects is potentially big. With a boosted resolution the EHT images can give more insights into the mass, size and other characteristics of black holes long sought after. In research work very much centered on estimates and models of data any chance at refining and getting a clearer picture is useful.

From someone who also spends a lot of time looking for things in the dark, we love to see this expanded use of data in new ways and say congrats to the PRIMO team!
Sources/Further Reading
- That Famous Black Hole Just Got Even Darker, The New York Times.
- The Image of the M87 Black Hole Reconstructed with PRIMO, The Astrophysical Journal Letters.
- The 1st-ever photo of a supermassive black hole just got an AI ‘makeover’ and it looks absolutely amazing, SPACE.COM
- First image of a black hole gets a makeover with AI, AP.
- Behind the Big Data: Revealing Our Galaxy’s Black Hole, CBL Data Recovery.
- Black Hole: It Takes Big Data to See The Big Picture, CBL Data Recovery.
Category: data recovery
Tags: artificial intelligence, big data, black hole, data, event horizon telescope, machine learning, nasa, science, space, technology